

LI Test
LI Test
When LLMs search the web, the retrieved web content adds to the LLM context window, filling it up with every search round. That growing context drives up token consumption, cost, and latency. We tested how Claude Sonnet 4.6 performs when it uses its own built-in web search compared to when it searches through a compact external API (in this case, the You.com Search API). In both instances we used Claude Sonnet 4.6 with identical prompts across 50 queries spanning four complexity tiers, all running with default LLM settings.
You.com web search results compared to Claude’s built-in web search.
How LLMs Use Web Search
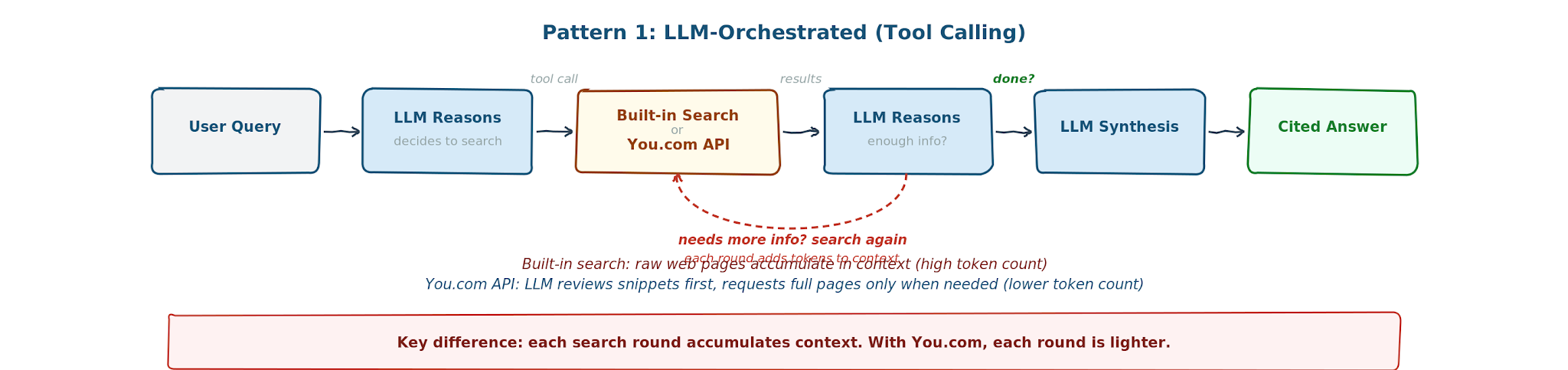
When you ask an LLM a question that requires current information—what is today's stock price, who won last night's game, what did the latest earnings call say—it first reasons that it needs to go find something. It issues a search, receives web content, and then reasons again over that content to produce a cited answer. These are fundamentally two different cognitive steps, and they happen whether the LLM uses a built-in search tool or an external API like You.com.
This behavior spans a wide range of queries. On one end, a simple lookup: "What is the current price of AAPL?" The LLM breaks once to search and returns. On the other end, deep research: "Which pharmaceutical companies have active GLP-1 drugs in Phase 3 trials?" The LLM may search 10 to 20 times, comparing clinical trial registries, recent filings, and press releases. In both cases, every piece of web content the LLM retrieves becomes context it has to carry, and that context directly determines how many tokens you pay for.
Everything above assumes the LLM controls the search, and that is how most workflows work today. But there is another way. The developer can control the search directly, decide what to look for, and hand curated content to the LLM. Both patterns are valid, but they trade off simplicity against control. Here is how each one works.
Pattern 1: LLM-Orchestrated (Tool Calling)
In this pattern, the LLM Claude Sonnet 4.6 controls the search. It decides when to search, what to search for, and calls a web search tool to go get it. This is how Claude works with its built-in web search. This is also how Claude works with You.com search, as another web search tool it can call instead of its built-in web search.The You.com search returns snippets first. Claude reviews them and decides whether the snippets are enough or whether it needs full page content through You.com's livecrawl. This gives Claude control over how much context it pulls in, rather than always ingesting raw web pages.
Example: "Write a story about Obama." The LLM decides to search for "obama facts" or "barack obama." You do not control the search terms; the LLM does. This is the simpler integration path.
Pattern 2: Developer-Orchestrated (Direct API)
In this pattern, the developer controls the search directly. This means you can fan out 10 parallel queries, apply your own filters and ranking, and feed curated context to the LLM. The LLM only does synthesis, never search.
Example: Same question: "Write a story about Obama." But now the developer controls the search directly. They fan out 10 parallel queries to You.com ("obama early life," "obama presidency highlights," "obama post-presidency"), filter and rank the results, and hand curated context to the LLM. The LLM writes the story from pre-selected sources.

This article focuses on the first pattern, the most common way teams use LLMs with web search today. The second pattern, however, unlocks even more flexibility via the You.com Search API.
In Pattern 1, built-in web search is convenient but the search is coupled to the LLM provider. The developer has no control over what gets retrieved, how many searches the LLM fires, or how much context accumulates in the conversation window. You.com gives the same simplicity with better economics, full observability, and provider independence.
What the Data Shows: Claude + You.com Search Wins on Every Metric
We ran 50 real-world queries across four complexity tiers on Claude Sonnet 4.6 with default Anthropic settings and then ran the same queries on Claude Sonnet 4.6 using the You.com Search API.
The results are consistent across every tier.
- Reduction in token bloat. Built-in search injects raw web content into the conversation context, and each search round adds to it. With You.com, Claude Sonnet 4.6 reviews compact snippets first and only pulls full pages when it needs them. The result: 61% fewer tokens per query on average (47k vs. 121k). To put that in perspective, 121k tokens is roughly 90,000 words of web content Claude Sonnet 4.6 has to carry for a single question.
- Lower cost. First, consider the search fees themselves: You.com charges half what Anthropic charges per search call. Second, and more significantly, LLM providers bill per input token. Every extra word of web content sitting in the context window costs money at inference time. When native search pulls 2.6x more content into context, that compounds directly into the invoice. Bottom line: 60% lower cost per query with You.com.
- Faster speed. Fewer search rounds and smaller payloads mean Claude Sonnet 4.6 spends less time waiting for results and less time processing them. You.com averaged 52 seconds per query vs. 87 seconds for native, 40% faster end to end.
- Quality holds or improves. Despite sending less content to Claude Sonnet 4.6, You.com produced higher-quality answers in 30 of 47 queries (average score 16.7/20 vs. 15.6/20). The scoring methodology is detailed in the "How We Measured Quality" section below. The short version: a separate LLM (GPT-5.4) blindly judged both answers for each query without knowing which search path produced them.
- Full observability. With You.com, the search is a standard tool call in the API request. The full payload appears in the API response: every source URL, every snippet, every token count. Developers can log it, debug it, and audit exactly what content Claude Sonnet 4.6 consumed. In contrast, built-in search is opaque— the final answer is visible but the raw web content Claude Sonnet 4.6 ingested to produce it is not.
- No LLM lock-in. You.com is a plain REST API that works with any LLM. Switch providers without rebuilding the search integration. Zero data retention on Team/Enterprise plans and SOC 2 certified.
This benchmark used the Claude API with the You.com Search API as a web search tool, but the same economics apply anywhere Claude calls You.com for search, including Claude Code and Claude Cowork connected to You.com Search via MCP. If your team is running web search queries through Claude today, switching to You.com reduces your bill immediately.
TLDR: developers using Claude with the You.com Search API get better answers faster and at less than half the cost.
Benchmark Results by Complexity Tier
The benchmark we ran included 50 queries— including news, finance, sports, healthcare, tech, regulation, and science—across four different complexity tiers. Of the 50, 47 completed (3 timed out on the native path). The per-query cost includes LLM inference plus search fees.
- Simple (12 queries). Single-fact lookups. One search, one answer. E.g., "What is the current price of NVIDIA stock?" or "What were the Powerball winning numbers?"
- Moderate Synthesis (18 queries). Requires reading and combining information from a few sources. E.g., "Summarize the EU AI Act enforcement updates in 2026" or "What are the latest developments in weight loss drugs?"
- Complex Multi-Source (11 queries). Cross-referencing multiple entities or datasets. E.g., "Compare the latest inflation rates, interest rates, and GDP growth for the US, EU, and Japan" or "What are the current market caps and PE ratios for the Magnificent 7?"
- Deep Research (6 queries). Exhaustive enumeration requiring 10-20+ searches. E.g., "List all commercial nuclear fusion companies that have raised over $100M" or "Which cities worldwide have implemented congestion pricing?"
Cost = average per query (LLM inference + search fees). Latency = average wall-clock time per query. Token Ratio = Native tokens / You.com tokens.
On average, built-in search fired 7.5 searches pulling 75 sources per query vs. 4.8 searches and 28 sources for You.com. The gap is widest on deep research queries.
Here is how the results break down across the four complexity tiers:
- Cost scales with complexity. Simple queries cost pennies on either path. The savings compound on complex and deep research queries, where built-in search can cost 5-10x more per query than simple ones.
- Fewer searches, same quality. You.com consistently uses fewer search calls across every tier. This is because Claude Sonnet 4.6 reviews snippets first and only requests full pages when needed, so each search round is more targeted.
- Deep research is where it matters most. Built-in search fires 21.7 searches per deep research query vs. 12.3 for You.com. That gap drives the token bloat, cost, and latency differences.
- The latency gap widens with complexity. Simple queries are fast on both paths. On complex and deep research queries, built-in search takes 2-3 minutes while You.com stays under 2.5 minutes.
How We Measured Quality
Measuring answer quality for web search is tricky because there is no ground truth to compare against. The web is live, answers change daily, and what counts as a "good" answer depends on the question. Our approach: use a separate LLM (GPT-5.4) as a blind judge. For each query, the judge receives both answers side by side in randomized order, labeled only as "Answer A" and "Answer B." It does not know which came from You.com and which came from native search. We use a different model family as judge (GPT judging Claude outputs) to avoid any self-preference bias.
The judge scores each answer on four dimensions, each rated 1 to 5:
- Completeness (1-5): Does the answer address all parts of the question? A score of 1 means major aspects are missing; 5 means every part of the question is thoroughly addressed.
- Relevance (1-5): Is the information directly relevant to what was asked, or does it include tangential content? A score of 5 means everything in the answer serves the query.
- Specificity (1-5): Does the answer include concrete data points (numbers, dates, names) rather than vague generalities? A score of 5 means the answer is rich with verifiable specifics.
- Citation Quality (1-5): Are sources cited, and do they appear credible and traceable? A score of 5 means claims are backed by specific, identifiable sources.
The four scores sum to a maximum of 20 per answer. The judge also declares an overall verdict: of the 47 queries, which answer is better, or whether they are comparable.
TLDR: You.com sends less content to Claude Sonnet 4.6, but the content it sends is more targeted. Claude Sonnet 4.6 reviews the snippets and only requests full pages when needed. This produces answers that are at least as good, and in most cases better, than what Claude Sonnet 4.6 produces when it ingests everything from built-in search.
Methodology Notes
Both paths used Anthropic's Messages API. Native search used Anthropic's web_search_20260209 tool with default settings, including code execution enabled. Code execution is a feature where Claude Sonnet 4.6 can write and run small programs to trigger additional searches dynamically. We left it on because that is what a developer gets out of the box when they add the web search tool to a Claude API call with no additional parameters.
Three of the 50 queries timed out on the native path. These were deep research and complex queries where built-in search triggered 15-20+ consecutive search rounds, causing the API connection to reset after three-to-five minutes of continuous processing. You.com completed those same queries successfully., but only scored the 47 that completed on both paths for a fair apples-to-apples comparison.
For completeness, we also ran this benchmark with code execution disabled. The results followed the same pattern: You.com delivered lower cost, fewer tokens, and comparable or better quality. However, code execution is Claude's default behavior, and disabling it limits Claude Sonnet 4.6's ability to dynamically trigger additional searches when needed. We recommend testing with default settings, which is what this report reflects.
Developers using Claude with the You.com Search API get better answers, faster, at less than half the cost. This applies whether you use the Claude API directly, or Claude Code and Claude Cowork connected to You.com Search via MCP. If your team is running web search queries through Claude today, switching to You.com reduces your bill immediately.
Try it yourself: We ship a self-contained Python toolkit with a side-by-side comparison runner, blind judge, and batch benchmark script. Add your API keys and run it against your own queries. Contact your You.com account team or visit you.com/platform to get started.
Appendix: The 50 Benchmark Queries
The full set of queries used in this benchmark, organized by complexity tier. These were selected to represent the range of real-world web search use cases: from simple lookups to deep multi-source research.
Total Cost (47 completed queries): Native $22.25 vs. You.com $8.90
Cost breakdown: LLM inference at $3/1M input tokens + $15/1M output tokens (Claude Sonnet 4.6 pricing) + search fees (You.com: $5 per 1,000 queries; Anthropic native: $10 per 1,000 searches). Average per-query cost: Native $0.47, You.com $0.19.
Featured resources.
.webp)
Paying 10x More After Google’s num=100 Change? Migrate to You.com in Under 10 Minutes
September 18, 2025
Blog

September 2025 API Roundup: Introducing Express & Contents APIs
September 16, 2025
Blog

You.com vs. Microsoft Copilot: How They Compare for Enterprise Teams
September 10, 2025
Blog
All resources.
Browse our complete collection of tools, guides, and expert insights — helping your team turn AI into ROI.
.webp)
What Are AI Search Engines and How Do They Work?
January 29, 2026
Blog

How Richard Socher, Inventor of Prompt Engineering, Built a $1.5B AI Search Company
January 29, 2026
Blog
.jpg)
What Is AI Search Infrastructure?
January 28, 2026
Guides

AI in 2026: Inside the Future-Shaping Predictions from You.com Co-Founders
January 27, 2026
Blog
.webp)
What Is AI Grounding and How Does it Work?
January 26, 2026
Guides

2026 AI Predictions: Insights from You.com Co-Founders
January 23, 2026
Guides
.jpg)
What Is Model Context Protocol (MCP)?
January 22, 2026
Blog
.jpg)
What the Heck Are Vertical Search Indexes?
January 20, 2026
Blog